Duplicated context, context locals, asynchronous processing and propagation
When using a traditional, blocking, and synchronous framework, processing of each request is performed in a dedicated thread.
So, the same thread is used for the entire processing.
You know that this thread will not be used to execute anything else until the completion of the processing.
When you need to propagate data along the processing, such as the security principal or a trace id, you can use ThreadLocals.
The propagated data is cleared once the processing is complete.
When using a reactive and asynchronous execution model, you cannot use the same mechanism.
To avoid using many process threads, and reduce resource usage (and also increase the concurrency of the application), the same thread can be used to handle multiple concurrent processing.
Thus, you cannot use ThreadLocals as the values would be leaked between the various concurrent processing.
Vert.x duplicated context is a construct that provides the same kind of propagation but for asynchronous processing. It can also be used with synchronous code.
This document explains duplicated contexts, how to retrieve one, use it, and how it’s propagated along the (asynchronous) processing.
The reactive model
| This section is not an explanation of the reactive model. Refer to that the Quarkus Reactive Architecture for more details. |
Under the hood, Quarkus uses a reactive engine. This engine provides the efficiency and concurrency to cope with modern, containerized, and cloud-native applications.
For example, when you use Quarkus REST (formerly RESTEasy Reactive) or gRPC, Quarkus can invoke your business logic on I/O threads. These threads are named event loops and implement a multi-reactor pattern.
When using the imperative model, Quarkus associates a worker thread to each processing unit (like an HTTP request or a gRPC invocation). That thread is dedicated to this specific processing until the processing completes. Thus, you can use Thread Locals to propagate data along the processing, and no other processing unit will use that thread until the completion of the current one.
With the reactive model, the code runs on event loop threads. These event loops execute multiple concurrent processing units. For example, the same event loop can handle multiple concurrent HTTP requests. The following picture illustrates this reactive execution model:
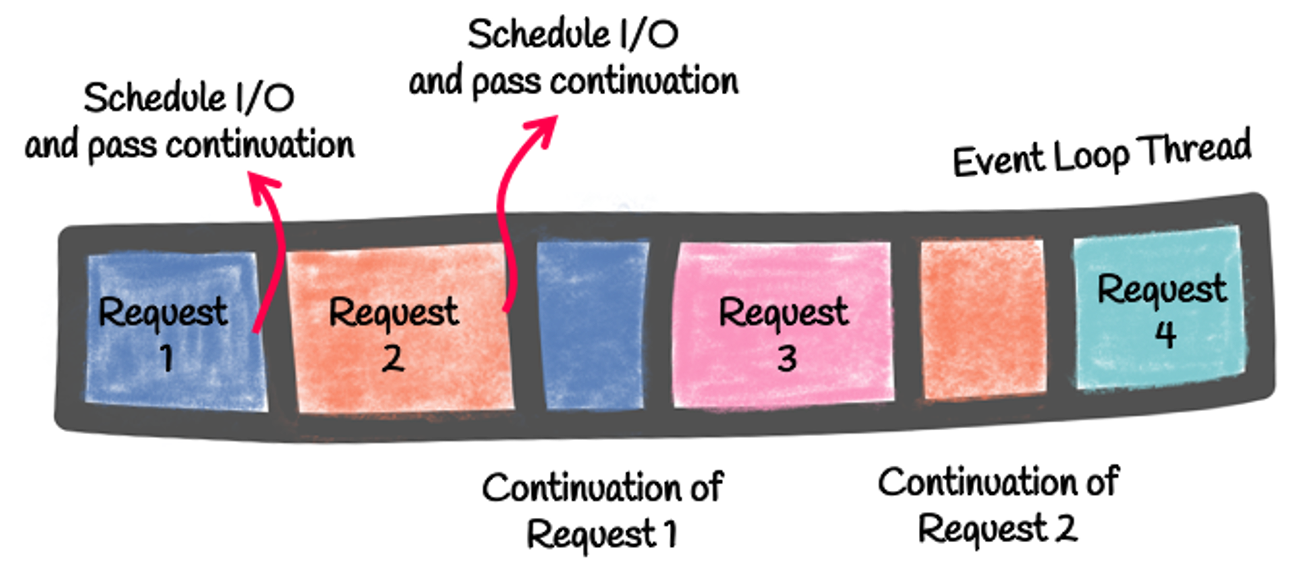
You must NEVER block these event loops. If you do, the whole model collapses. Thus, when the processing of an HTTP request needs to execute an I/O operation (such as calling an external service), it:
-
schedules the operation,
-
passes a continuation (the code to call when the I/O completes),
-
releases the thread.
That thread can then handle another concurrent request. When the scheduled operation completes, it executes the passed continuation on the same event loop.
That model is particularly efficient (low number of threads) and performant (avoid context switches). However, it requires a different development model, and you cannot use Thread Locals, as the concurrent requests would see the same value. Indeed, they are all processed by the same thread: the event loop.
The MicroProfile Context Propagation specification addresses this issue. It saves and restores the values stored in thread locals whenever we switch to another processing unit. However, that model is expensive. Context locals (also known as duplicated context) is another way to do this and requires fewer mechanics.
Context and duplicated context
In Quarkus, when you execute reactive code, you run in a Context, representing the execution thread (event loop or worker thread).
@GET
@NonBlocking // Force the usage of the event loop
@Path("/hello1")
public String hello1() {
Context context = Vertx.currentContext();
return "Hello, you are running on context: %s and on thread %s".formatted(context, Thread.currentThread()); (1)
}
@GET
@Path("/hello2")
public String hello2() { // Called on a worker thread (because it has a blocking signature)
Context context = Vertx.currentContext();
return "Hello, you are running on context: %s and on thread %s".formatted(context, Thread.currentThread()); (2)
}| 1 | Produces: Hello 1, you are running on context: io.vertx.core.impl.DuplicatedContext@5dc42d4f and on thread Thread[vert.x-eventloop-thread-1,5,main] - so invoked on an event loop. |
| 2 | Produces: Hello 2, you are running on context: io.vertx.core.impl.DuplicatedContext@41781ccb and on thread Thread[executor-thread-1,5,main] - so invoked on a worker thread. |
With this Context object, you can schedule operations in the same context. The context is handy for executing the continuation on the same event loop (as contexts are attached to event loops), as described in the picture above. For example, when you need to call something asynchronous, you capture the current context, and when the response arrives, it invokes the continuation in that context:
public Uni<String> invoke() {
Context context = Vertx.currentContext();
return invokeRemoteService()
.emitOn(runnable -> context.runOnContext(runnable)); (1)
}| 1 | Emit the result in the same context. |
| Most Quarkus clients do this automatically, invoking the continuation in the proper context. |
There are two levels of contexts:
-
the root contexts representing the event loop, and thus cannot be used to propagate data without leaking it between concurrent processing
-
the duplicated contexts, which are based on a root context, but are NOT shared and represent the processing unit
Thus, a duplicated context is associated with each processing unit. A duplicated context is still associated with a root context, and scheduling operations using a duplicated context run them in the associated root context. But, unlike the root context, they are not shared between processing units. Yet, continuations of a processing unit use the same duplicated context. So, in the previous code snippet, the continuation is not only called on the same event loop but on the same duplicated context (supposing that the captured context is a duplicated context, more on that later).
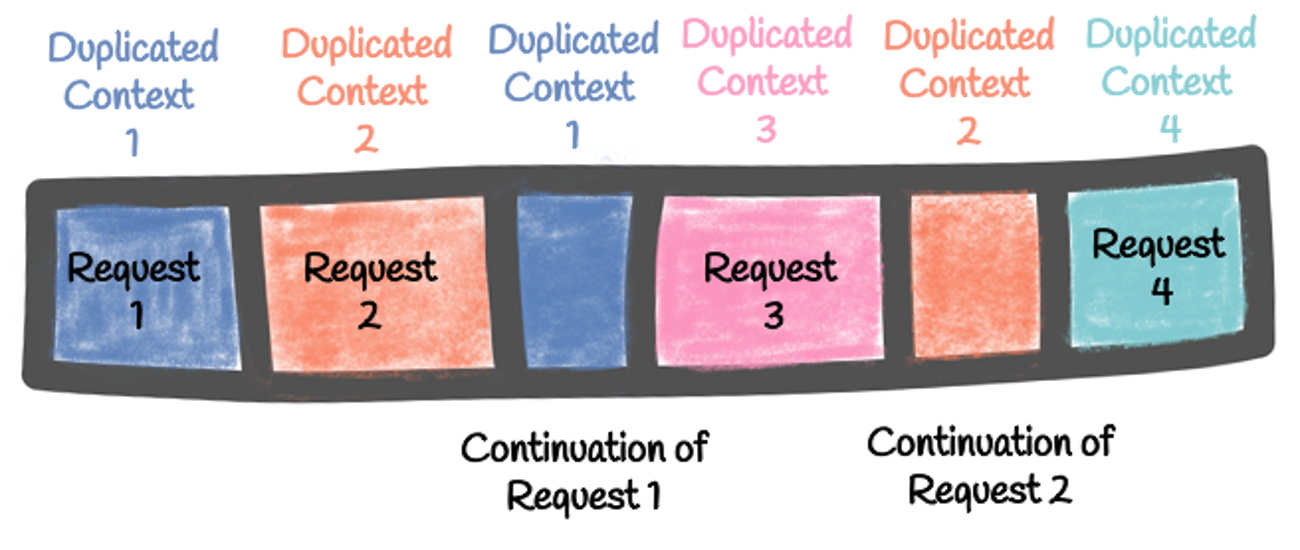
Context local data
When executed in a duplicated context, the code can store data without sharing it with the other concurrent processing. So, you can store, retrieve and remove local data. The continuation invokes on the same duplicated context, will have access to that data:
import io.smallrye.common.vertx.ContextLocals;
AtomicInteger counter = new AtomicInteger();
public Uni<String> invoke() {
Context context = Vertx.currentContext();
ContextLocals.put("message", "hello");
ContextLocals.put("id", counter.incrementAndGet());
return invokeRemoteService()
.emitOn(runnable -> context.runOnContext(runnable))
.map(res -> {
// Can still access the context local data
// `get(...)` returns an Optional
String msg = ContextLocals.<String>get("message").orElseThrow();
Integer id = ContextLocals.<Integer>get("id").orElseThrow();
return "%s - %s - %d".formatted(res, msg, id);
});
}
The previous code snippet uses io.smallrye.common.vertx.ContextLocals, which eases access to the local data.
You can also access them using Vertx.currentContext().getLocal("key").
|
Context local data provides an efficient way to propagate objects during a reactive execution. Tracing metadata, metrics, and sessions can be stored and retrieved safely.
Context locals restrictions
However, such a feature must only be used with duplicated contexts. As said above, it’s transparent for the code. A duplicated context is a context, so they expose the same API.
In Quarkus, access to the local data is restricted to duplicated contexts.
If you try to access local data from a root context, it throws an UnsupportedOperationException.
It prevents accessing data shared among different units of processing.
java.lang.UnsupportedOperationException: Access to Context.putLocal(), Context.getLocal() and Context.removeLocal() are forbidden from a 'root' context as it can leak data between unrelated processing. Make sure the method runs on a 'duplicated' (local) Context.Safe context
You can mark a context safe. It is meant for other extensions to integrate with to help identify which contexts are isolated and guarantee access by a unique thread. Hibernate Reactive uses this feature to check if the current context is safe to store the currently opened session to protect users from mistakenly interleaving multiple reactive operations that could unintentionally share the same session.
Vert.x web will create a new duplicated context for each http web request; Quarkus REST will mark such contexts as safe. Other extensions should follow a similar pattern when they are setting up a new context that is safe to be used for a local context guaranteeing sequential use, non-concurrent access, and scoped to the current reactive chain as a convenience not to have to pass a "context" object along explicitly.
In other cases, it might be helpful to mark the current context as not safe instead explicitly; for example, if an existing context needs to be shared across multiple workers to process some operations in parallel: by marking and un-marking appropriately the same context can have spans in which it’s safe, followed by spans in which it’s not safe.
To mark a context as safe, you can:
-
Use the
io.quarkus.vertx.SafeVertxContextannotation -
Use the
io.quarkus.vertx.core.runtime.context.VertxContextSafetyToggleclass
By using the io.quarkus.vertx.core.runtime.context.VertxContextSafetyToggle class, the current context can be explicitly marked as safe, or it can be explicitly marked as unsafe; there’s a third state which is the default of any new context: unmarked.
The default is to consider any unmarked context to be unsafe, unless the system property io.quarkus.vertx.core.runtime.context.VertxContextSafetyToggle.UNRESTRICTED_BY_DEFAULT is set to true;
The SafeVertxContext annotation marks the current duplicated context as safe and invokes the annotated method if the context is unmarked or already marked as safe.
If the context is marked as unsafe, you can force it to be safe using the force=true parameter.
However, this possibility must be used carefully.
The @SafeVertxContext annotation is a CDI interceptor binding annotation.
Therefore, it only works for CDI beans and on non-private methods.
|
Extensions supporting duplicated contexts
In general, Quarkus invokes reactive code on duplicated contexts. So it can safely access the local data. It is the case with:
-
Quarkus REST
-
gRPC
-
Reactive Routes
-
Vert.x Event Bus
@ConsumeEvent -
REST Client
-
Reactive Messaging (Kafka, AMQP)
-
Funqy
-
Quarkus scheduler and Quartz
-
Redis Client (for the pub/sub commands)
-
GraphQL
Distinguish between root and duplicated contexts
You can distinguish between a root and a duplicated context using the following:
boolean isDuplicated = VertxContext.isDuplicatedContext(context);This code uses the io.smallrye.common.vertx.VertxContext helper class.
Duplicated contexts and mapped diagnostic context (MDC)
When using loggers, the MDC (contextual data added to the log messages) is stored in duplicated context when available. Check the logging reference guide for more details.
CDI request scope
In Quarkus, the CDI request scope is stored in a duplicated context, meaning it gets automatically propagated alongside the reactive processing of a request.
Reactive Messaging
The Kafka and AMQP connector creates a duplicated context for each message, implementing a message context. This message context is used for the complete message processing and thus can be used to propagate data.
See the Message Context documentation for further information.