Usando Apache Kafka Streams
Esta guía demuestra cómo su aplicación Quarkus puede utilizar la API de Apache Kafka Streams para implementar aplicaciones de procesamiento de flujos basadas en Apache Kafka.
Requisitos previos
To complete this guide, you need:
-
Roughly 30 minutes
-
An IDE
-
JDK 17+ installed with
JAVA_HOMEconfigured appropriately -
Apache Maven 3.9.16
-
Docker and Docker Compose or Podman, and Docker Compose
-
Optionally the Quarkus CLI if you want to use it
-
Optionally Mandrel or GraalVM installed and configured appropriately if you want to build a native executable (or Docker if you use a native container build)
Se recomienda haber leído antes el enlace Kafka quickstart.
|
La extensión de Quarkus para Kafka Streams permite ciclos de desarrollo muy rápidos al admitir el Modo de Desarrollo de Quarkus (por ejemplo, mediante Una configuración de desarrollo recomendada es contar con un productor que genere mensajes de prueba en los tópicos procesados a intervalos fijos, por ejemplo cada segundo, y observar los mensajes en los tópicos de salida de la aplicación de streaming utilizando una herramienta como Para obtener la mejor experiencia de desarrollo, recomendamos aplicar las siguientes configuraciones a su corredor de Kafka: Especifique también las siguientes configuraciones en su archivo En conjunto, estas configuraciones garantizarán que la aplicación pueda reconectarse muy rápidamente al corredor después de reiniciarse en el Modo de Desarrollo. |
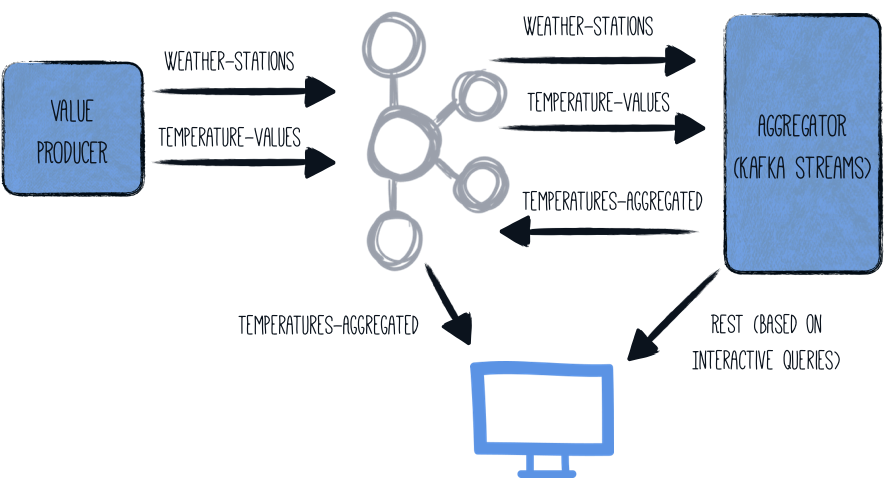
Arquitectura
En esta guía, vamos a generar valores de temperatura (aleatorios) en un componente llamado generator.
Estos valores están asociados a determinadas estaciones meteorológicas y se escriben en un tópico de Kafka ( temperature-values ).
Otro tópico (weather-stations) contiene únicamente los datos principales de las estaciones meteorológicas (id y nombre).
Un segundo componente (aggregator) lee de los dos tópicos de Kafka y los procesa en un flujo de streaming:
-
los dos tópicos se combinan según el ID de la estación meteorológica
-
para cada estación meteorológica se determinan la temperatura mínima, máxima y promedio
-
estos datos agregados se escriben en un tercer tópico (
temperatures-aggregated)
Los datos pueden examinarse inspeccionando el tópico de salida. Mediante la exposición de una consulta interactiva de Kafka Streams, el último resultado de cada estación meteorológica puede obtenerse alternativamente a través de una sencilla consulta REST.
La arquitectura general se ve así:
Solución
Recomendamos que siga las instrucciones de las siguientes secciones y cree la aplicación paso a paso. Sin embargo, también puede ir directamente al ejemplo completo.
Clone el repositorio Git: git clone https://github.com/quarkusio/quarkus-quickstarts.git o descargue un archivo.
La solución se encuentra en el directorio kafka-streams-quickstart.
Creación del proyecto Maven del productor
Primero, necesitamos un nuevo proyecto con el productor de valores de temperatura. Cree un nuevo proyecto con el siguiente comando:
For Windows users:
-
If using cmd, (don’t use backward slash
\and put everything on the same line) -
If using Powershell, wrap
-Dparameters in double quotes e.g."-DprojectArtifactId=kafka-streams-quickstart-producer"
Este comando genera un proyecto Maven, importando las extensiones de Mensajería Reactiva y el conector de Kafka.
Si ya tiene configurado su proyecto Quarkus, puede añadir la extensión messaging-kafka
a su proyecto ejecutando el siguiente comando en el directorio base de su proyecto:
quarkus extension add quarkus-messaging-kafka./mvnw quarkus:add-extension -Dextensions='quarkus-messaging-kafka'./gradlew addExtension --extensions='quarkus-messaging-kafka'Esto añadirá lo siguiente a su archivo de construcción:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-messaging-kafka</artifactId>
</dependency>implementation("io.quarkus:quarkus-messaging-kafka")El productor de valores de temperatura
Cree el archivo producer/src/main/java/org/acme/kafka/streams/producer/generator/ValuesGenerator.java,
con el siguiente contenido:
package org.acme.kafka.streams.producer.generator;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.time.Duration;
import java.time.Instant;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.Random;
import jakarta.enterprise.context.ApplicationScoped;
import io.smallrye.mutiny.Multi;
import io.smallrye.reactive.messaging.kafka.Record;
import org.eclipse.microprofile.reactive.messaging.Outgoing;
import org.jboss.logging.Logger;
/**
* A bean producing random temperature data every second.
* The values are written to a Kafka topic (temperature-values).
* Another topic contains the name of weather stations (weather-stations).
* The Kafka configuration is specified in the application configuration.
*/
@ApplicationScoped
public class ValuesGenerator {
private static final Logger LOG = Logger.getLogger(ValuesGenerator.class);
private Random random = new Random();
private List<WeatherStation> stations = List.of(
new WeatherStation(1, "Hamburg", 13),
new WeatherStation(2, "Snowdonia", 5),
new WeatherStation(3, "Boston", 11),
new WeatherStation(4, "Tokio", 16),
new WeatherStation(5, "Cusco", 12),
new WeatherStation(6, "Svalbard", -7),
new WeatherStation(7, "Porthsmouth", 11),
new WeatherStation(8, "Oslo", 7),
new WeatherStation(9, "Marrakesh", 20));
@Outgoing("temperature-values") (1)
public Multi<Record<Integer, String>> generate() {
return Multi.createFrom().ticks().every(Duration.ofMillis(500)) (2)
.onOverflow().drop()
.map(tick -> {
WeatherStation station = stations.get(random.nextInt(stations.size()));
double temperature = BigDecimal.valueOf(random.nextGaussian() * 15 + station.averageTemperature)
.setScale(1, RoundingMode.HALF_UP)
.doubleValue();
LOG.infov("station: {0}, temperature: {1}", station.name, temperature);
return Record.of(station.id, Instant.now() + ";" + temperature);
});
}
@Outgoing("weather-stations") (3)
public Multi<Record<Integer, String>> weatherStations() {
return Multi.createFrom().items(stations.stream()
.map(s -> Record.of(
s.id,
"{ \"id\" : " + s.id +
", \"name\" : \"" + s.name + "\" }"))
);
}
private static class WeatherStation {
int id;
String name;
int averageTemperature;
public WeatherStation(int id, String name, int averageTemperature) {
this.id = id;
this.name = name;
this.averageTemperature = averageTemperature;
}
}
}| 1 | Indique a Mensajería Reactiva que envíe los elementos de la Multi devuelta a temperature-values. |
| 2 | El método devuelve un flujo Mutiny ( Multi) que emite un valor de temperatura aleatorio cada 0,5 segundos. |
| 3 | Indique a Mensajería Reactiva que envíe los elementos de la Multi devuelta (lista estática de estaciones meteorológicas) a weather-stations. |
Ambos métodos devuelven un flujo reactivo cuyos elementos se envían a los flujos denominados temperature-values y weather-stations, respectivamente.
Configuración de los tópicos
Los dos canales se asignan a tópicos de Kafka utilizando el archivo de configuración de Quarkus application.properties.
Para ello, agregue lo siguiente al archivo producer/src/main/resources/application.properties:
# Configure the Kafka broker location
kafka.bootstrap.servers=localhost:9092
mp.messaging.outgoing.temperature-values.connector=smallrye-kafka
mp.messaging.outgoing.temperature-values.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.temperature-values.value.serializer=org.apache.kafka.common.serialization.StringSerializer
mp.messaging.outgoing.weather-stations.connector=smallrye-kafka
mp.messaging.outgoing.weather-stations.key.serializer=org.apache.kafka.common.serialization.IntegerSerializer
mp.messaging.outgoing.weather-stations.value.serializer=org.apache.kafka.common.serialization.StringSerializerEsta configuración define el servidor bootstrap de Kafka, los dos tópicos y los (de)serializadores correspondientes. Más detalles sobre las diferentes opciones de configuración están disponibles en la documentación de Kafka, en las secciones Configuración del productor y Configuración del consumidor.
Creación del proyecto Maven del agregador
Con la aplicación productora en su lugar, es momento de implementar la aplicación agregadora real, que ejecutará el flujo de Kafka Streams. Cree otro proyecto de la siguiente manera:
For Windows users:
-
If using cmd, (don’t use backward slash
\and put everything on the same line) -
If using Powershell, wrap
-Dparameters in double quotes e.g."-DprojectArtifactId=kafka-streams-quickstart-aggregator"
Esto crea el proyecto aggregator con la extensión de Quarkus para Kafka Streams y con el soporte de Jackson para Quarkus REST (anteriormente RESTEasy Reactive).
Si ya tiene su proyecto Quarkus configurado, puede añadir la extensión kafka-streams
a su proyecto ejecutando el siguiente comando en el directorio base del proyecto:
quarkus extension add kafka-streams./mvnw quarkus:add-extension -Dextensions='kafka-streams'./gradlew addExtension --extensions='kafka-streams'Esto añadirá lo siguiente a su pom.xml:
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-kafka-streams</artifactId>
</dependency>implementation("io.quarkus:quarkus-kafka-streams")Implementación del flujo
Comencemos la implementación de la aplicación de procesamiento de flujos creando algunos objetos de valor para representar las mediciones de temperatura, las estaciones meteorológicas y para llevar el registro de los valores agregados.
Primero, cree el archivo aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStation.java,'
que representa una estación meteorológica, con el siguiente contenido:
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection (1)
public class WeatherStation {
public int id;
public String name;
}| 1 | La anotación @RegisterForReflection indica a Quarkus que mantenga la clase y sus miembros durante la compilación nativa. Puede encontrar más detalles sobre la anotación @RegisterForReflection en la página consejos para aplicaciones nativas. |
Luego, cree el archivo aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/TemperatureMeasurement.java,
que representa las mediciones de temperatura de una estación determinada:
package org.acme.kafka.streams.aggregator.model;
import java.time.Instant;
public class TemperatureMeasurement {
public int stationId;
public String stationName;
public Instant timestamp;
public double value;
public TemperatureMeasurement(int stationId, String stationName, Instant timestamp,
double value) {
this.stationId = stationId;
this.stationName = stationName;
this.timestamp = timestamp;
this.value = value;
}
}Y finalmente, aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/Aggregation.java,
que se utilizará para llevar el seguimiento de los valores agregados mientras los eventos se procesan en el flujo de transmisión:
package org.acme.kafka.streams.aggregator.model;
import java.math.BigDecimal;
import java.math.RoundingMode;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class Aggregation {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double sum;
public double avg;
public Aggregation updateFrom(TemperatureMeasurement measurement) {
stationId = measurement.stationId;
stationName = measurement.stationName;
count++;
sum += measurement.value;
avg = BigDecimal.valueOf(sum / count)
.setScale(1, RoundingMode.HALF_UP).doubleValue();
min = Math.min(min, measurement.value);
max = Math.max(max, measurement.value);
return this;
}
}A continuación, vamos a crear la implementación de la consulta de flujo en sí en el archivo aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/TopologyProducer.java.
Todo lo que necesitamos hacer para ello es declarar un método productor CDI que devuelva la Topology de Kafka Streams;
la extensión de Quarkus se encargará de configurar, iniciar y detener el motor real de Kafka Streams.
package org.acme.kafka.streams.aggregator.streams;
import java.time.Instant;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.enterprise.inject.Produces;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.TemperatureMeasurement;
import org.acme.kafka.streams.aggregator.model.WeatherStation;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.Topology;
import org.apache.kafka.streams.kstream.Consumed;
import org.apache.kafka.streams.kstream.GlobalKTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueBytesStoreSupplier;
import org.apache.kafka.streams.state.Stores;
import io.quarkus.kafka.client.serialization.ObjectMapperSerde;
@ApplicationScoped
public class TopologyProducer {
static final String WEATHER_STATIONS_STORE = "weather-stations-store";
private static final String WEATHER_STATIONS_TOPIC = "weather-stations";
private static final String TEMPERATURE_VALUES_TOPIC = "temperature-values";
private static final String TEMPERATURES_AGGREGATED_TOPIC = "temperatures-aggregated";
@Produces
public Topology buildTopology() {
StreamsBuilder builder = new StreamsBuilder();
ObjectMapperSerde<WeatherStation> weatherStationSerde = new ObjectMapperSerde<>(
WeatherStation.class);
ObjectMapperSerde<Aggregation> aggregationSerde = new ObjectMapperSerde<>(Aggregation.class);
KeyValueBytesStoreSupplier storeSupplier = Stores.persistentKeyValueStore(
WEATHER_STATIONS_STORE);
GlobalKTable<Integer, WeatherStation> stations = builder.globalTable( (1)
WEATHER_STATIONS_TOPIC,
Consumed.with(Serdes.Integer(), weatherStationSerde));
builder.stream( (2)
TEMPERATURE_VALUES_TOPIC,
Consumed.with(Serdes.Integer(), Serdes.String())
)
.join( (3)
stations,
(stationId, timestampAndValue) -> stationId,
(timestampAndValue, station) -> {
String[] parts = timestampAndValue.split(";");
return new TemperatureMeasurement(station.id, station.name,
Instant.parse(parts[0]), Double.valueOf(parts[1]));
}
)
.groupByKey() (4)
.aggregate( (5)
Aggregation::new,
(stationId, value, aggregation) -> aggregation.updateFrom(value),
Materialized.<Integer, Aggregation> as(storeSupplier)
.withKeySerde(Serdes.Integer())
.withValueSerde(aggregationSerde)
)
.toStream()
.to( (6)
TEMPERATURES_AGGREGATED_TOPIC,
Produced.with(Serdes.Integer(), aggregationSerde)
);
return builder.build();
}
}| 1 | La tabla weather-stations se lee en un GlobalKTable, representando el estado actual de cada estación meteorológica |
| 2 | El tópico temperature-values se lee en un KStream; cada vez que llega un nuevo mensaje a este tópico, el flujo se procesará para esta medición |
| 3 | El mensaje del tópico temperature-values se une con la estación meteorológica correspondiente, utilizando la clave del tópico (id de la estación meteorológica); el resultado de la unión contiene los datos de la medición y el mensaje asociado de la estación meteorológica |
| 4 | Los valores se agrupan por la clave del mensaje (el id de la estación meteorológica) |
| 5 | Dentro de cada grupo, todas las mediciones de esa estación se agregan, manteniendo un registro de los valores mínimos y máximos y calculando el valor promedio de todas las mediciones de esa estación (consulte el tipo Aggregation) |
| 6 | Los resultados del flujo se escriben en el tópico temperatures-aggregated |
La extensión de Kafka Streams se configura mediante el archivo de configuración de Quarkus application.properties.
Cree el archivo aggregator/src/main/resources/application.properties con el siguiente contenido:
quarkus.kafka-streams.bootstrap-servers=localhost:9092
quarkus.kafka-streams.application-server=${hostname}:8080
quarkus.kafka-streams.topics=weather-stations,temperature-values
# pass-through options
kafka-streams.cache.max.bytes.buffering=10240
kafka-streams.commit.interval.ms=1000
kafka-streams.metadata.max.age.ms=500
kafka-streams.auto.offset.reset=earliest
kafka-streams.metrics.recording.level=DEBUGLas opciones con el prefijo quarkus.kafka-streams se pueden cambiar dinámicamente al iniciar la aplicación,
por ejemplo, mediante variables de entorno o propiedades del sistema.
bootstrap-servers y application-server se asignan a las propiedades de Kafka Streams bootstrap.servers y application.server, respectivamente.
topics es específico de Quarkus: la aplicación esperará a que existan todos los tópicos indicados antes de iniciar el motor de Kafka Streams.
Esto se hace para esperar de manera ordenada la creación de tópicos que aún no existen al iniciar la aplicación.
Como alternativa, puede usar kafka.bootstrap.servers en lugar de quarkus.kafka-streams.bootstrap-servers, tal como se hizo en el proyecto generator mencionado anteriormente.
|
|
Una vez que esté listo para promover su aplicación a producción, considere cambiar los valores de configuración anteriores. Mientras que |
Todas las propiedades dentro del espacio de nombres kafka-streams se pasan tal cual al motor de Kafka Streams.
Cambiar sus valores requiere una reconstrucción de la aplicación.
Construcción y ejecución de las aplicaciones
Ahora podemos compilar las aplicaciones producer y aggregator:
./mvnw clean package -f producer/pom.xml
./mvnw clean package -f aggregator/pom.xmlEn lugar de ejecutarlas directamente en la máquina host utilizando el modo dev de Quarkus,
vamos a empaquetarlas en imágenes de contenedor y lanzarlas mediante Docker Compose.
Esto se hace con el fin de demostrar cómo escalar la agregación del aggregator a múltiples nodos más adelante.
El Dockerfile creado por Quarkus por defecto necesita un ajuste para la aplicación aggregator con el fin de ejecutar el flujo de Kafka Streams.
Para ello, edite el archivo aggregator/src/main/docker/Dockerfile.jvm y reemplace la línea FROM fabric8/java-alpine-openjdk8-jre por FROM fabric8/java-centos-openjdk8-jdk.
Next create a Docker Compose file (docker-compose.yaml) for spinning up the two applications as well as Apache Kafka like so:
services:
kafka:
image: quay.io/strimzi/kafka:latest-kafka-4.1.0
command: [
"sh", "-c",
"./bin/kafka-storage.sh format --standalone -t $$(./bin/kafka-storage.sh random-uuid) -c ./config/server.properties && ./bin/kafka-server-start.sh ./config/server.properties --override advertised.listeners=$${KAFKA_ADVERTISED_LISTENERS} --override num.partitions=$${KAFKA_NUM_PARTITIONS} --override group.min.session.timeout.ms=$${KAFKA_GROUP_MIN_SESSION_TIMEOUT_MS}"
]
ports:
- "9092:9092"
environment:
LOG_DIR: "/tmp/logs"
KAFKA_ADVERTISED_LISTENERS: 'PLAINTEXT://kafka:9092'
KAFKA_NUM_PARTITIONS: 3
KAFKA_GROUP_MIN_SESSION_TIMEOUT_MS: 100
networks:
- kafkastreams-network
producer:
image: quarkus-quickstarts/kafka-streams-producer:1.0
build:
context: producer
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
KAFKA_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
aggregator:
image: quarkus-quickstarts/kafka-streams-aggregator:1.0
build:
context: aggregator
dockerfile: src/main/docker/Dockerfile.${QUARKUS_MODE:-jvm}
environment:
QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS: kafka:9092
networks:
- kafkastreams-network
networks:
kafkastreams-network:
name: ksPara iniciar todos los contenedores, construyendo las imágenes de contenedor producer y aggregator,
ejecute docker-compose up --build.
En lugar de QUARKUS_KAFKA_STREAMS_BOOTSTRAP_SERVERS, puede usar KAFKA_BOOTSTRAP_SERVERS.
|
Debería ver declaraciones de registro de la aplicación producer sobre los mensajes enviados al tópico "temperature-values".
Ahora ejecute una instancia de la imagen debezium/tooling, conectándola a la misma red en la que se ejecutan todos los demás contenedores. Esta imagen proporciona varias herramientas útiles, como kafkacat y httpie:
docker run --tty --rm -i --network ks debezium/tooling:latestDentro del contenedor de herramientas, ejecute kafkacat para examinar los resultados de la transmisión del flujo:
kafkacat -b kafka:9092 -C -o beginning -q -t temperatures-aggregated
{"avg":34.7,"count":4,"max":49.4,"min":16.8,"stationId":9,"stationName":"Marrakesh","sum":138.8}
{"avg":15.7,"count":1,"max":15.7,"min":15.7,"stationId":2,"stationName":"Snowdonia","sum":15.7}
{"avg":12.8,"count":7,"max":25.5,"min":-13.8,"stationId":7,"stationName":"Porthsmouth","sum":89.7}
...Debería ver llegar nuevos valores a medida que el productor continúa emitiendo mediciones de temperatura, cada valor en el tópico de salida mostrando los valores mínimo, máximo y promedio de temperatura de la estación meteorológica representada.
Consultas interactivas
Suscribirse al tópico temperatures-aggregated es una excelente manera de reaccionar ante cualquier nuevo valor de temperatura.
Sin embargo, es un poco ineficiente si solo le interesa el último valor agregado de una estación meteorológica específica.
Aquí es donde las consultas interactivas de Kafka Streams destacan:
permiten consultar directamente el almacén de estado subyacente del flujo para obtener el valor asociado a una clave determinada.
Al exponer un endpoint REST simple que consulte el almacén de estado,
se puede recuperar el resultado de la última agregación sin necesidad de suscribirse a ningún tópico de Kafka.
Comencemos creando una nueva clase InteractiveQueries en el archivo aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/InteractiveQueries.java:
un método más para la clase KafkaStreamsPipeline que obtiene el estado actual para una clave determinada:
package org.acme.kafka.streams.aggregator.streams;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import org.acme.kafka.streams.aggregator.model.Aggregation;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.errors.InvalidStateStoreException;
import org.apache.kafka.streams.state.QueryableStoreTypes;
import org.apache.kafka.streams.state.ReadOnlyKeyValueStore;
@ApplicationScoped
public class InteractiveQueries {
@Inject
KafkaStreams streams;
public GetWeatherStationDataResult getWeatherStationData(int id) {
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result)); (1)
}
else {
return GetWeatherStationDataResult.notFound(); (2)
}
}
private ReadOnlyKeyValueStore<Integer, Aggregation> getWeatherStationStore() {
while (true) {
try {
return streams.store(StoreQueryParameters
.fromNameAndType(TopologyProducer.WEATHER_STATIONS_STORE, QueryableStoreTypes.keyValueStore()));
} catch (InvalidStateStoreException e) {
// ignore, store not ready yet
}
}
}
}| 1 | Se encontró un valor para la estación indicada, por lo que se devolverá ese valor |
| 2 | No se ha encontrado ningún valor, ya sea porque se ha consultado una estación inexistente o porque todavía no existe ninguna medición para la estación indicada |
También cree el tipo de retorno del método en el archivo aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/GetWeatherStationDataResult.java:
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null);
private final WeatherStationData result;
private GetWeatherStationDataResult(WeatherStationData result) {
this.result = result;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
}También cree aggregator/src/main/java/org/acme/kafka/streams/aggregator/model/WeatherStationData.java,
que representa el resultado de agregación actual de una estación meteorológica:
package org.acme.kafka.streams.aggregator.model;
import io.quarkus.runtime.annotations.RegisterForReflection;
@RegisterForReflection
public class WeatherStationData {
public int stationId;
public String stationName;
public double min = Double.MAX_VALUE;
public double max = Double.MIN_VALUE;
public int count;
public double avg;
private WeatherStationData(int stationId, String stationName, double min, double max,
int count, double avg) {
this.stationId = stationId;
this.stationName = stationName;
this.min = min;
this.max = max;
this.count = count;
this.avg = avg;
}
public static WeatherStationData from(Aggregation aggregation) {
return new WeatherStationData(
aggregation.stationId,
aggregation.stationName,
aggregation.min,
aggregation.max,
aggregation.count,
aggregation.avg);
}
}Ahora podemos agregar una ruta REST simple (aggregator/src/main/java/org/acme/kafka/streams/aggregator/rest/WeatherStationEndpoint.java),
que invoque getWeatherStationData() y devuelva los datos al cliente:
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else {
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
}| 1 | Dependiendo de si se obtuvo un valor, devuelva ese valor o una respuesta 404 |
Con este código en su lugar, es hora de reconstruir la aplicación y el servicio aggregator en Docker Compose:
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -dEsto reconstruirá el contenedor aggregator y reiniciará el servicio.
Una vez completado, puede invocar la API REST del servicio para obtener los datos de temperatura de una de las estaciones existentes.
Para ello, puede usar httpie en el contenedor de herramientas que se lanzó anteriormente:
http aggregator:8080/weather-stations/data/1
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 85
Content-Type: application/json
Date: Tue, 18 Jun 2019 19:29:16 GMT
{
"avg": 12.9,
"count": 146,
"max": 41.0,
"min": -25.6,
"stationId": 1,
"stationName": "Hamburg"
}Escalado horizontal
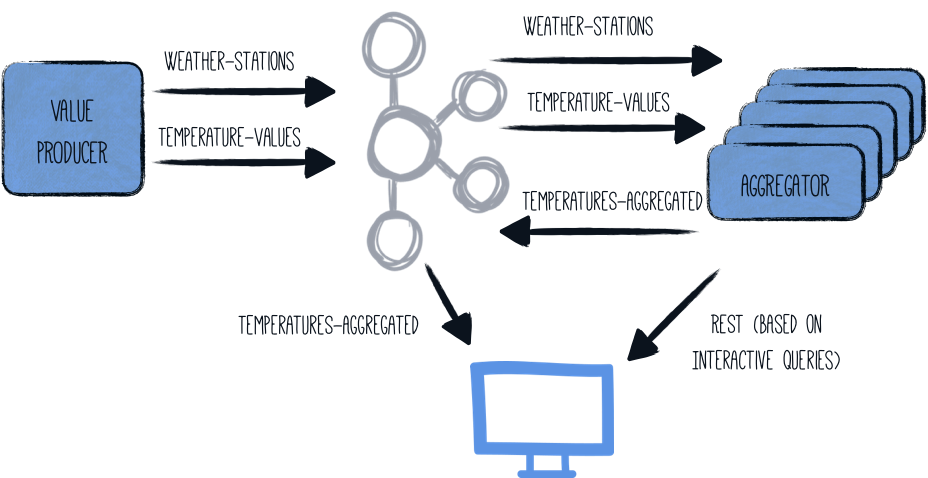
Una característica muy interesante de las aplicaciones Kafka Streams es que pueden escalarse horizontalmente, es decir, la carga y el estado pueden distribuirse entre múltiples instancias de la aplicación que ejecutan el mismo flujo. Cada nodo contendrá entonces un subconjunto de los resultados de agregación, pero Kafka Streams le proporciona una API para obtener información sobre qué nodo aloja una clave determinada. La aplicación puede entonces recuperar los datos directamente de la otra instancia, o simplemente indicar al cliente la ubicación de ese otro nodo.
Lanzar múltiples instancias de la aplicación aggregator hará que la arquitectura general se vea así:
La clase InteractiveQueries debe ajustarse ligeramente para adaptarse a esta arquitectura distribuida:
public GetWeatherStationDataResult getWeatherStationData(int id) {
StreamsMetadata metadata = streams.metadataForKey( (1)
TopologyProducer.WEATHER_STATIONS_STORE,
id,
Serdes.Integer().serializer()
);
if (metadata == null || metadata == StreamsMetadata.NOT_AVAILABLE) {
LOG.warn("Found no metadata for key {}", id);
return GetWeatherStationDataResult.notFound();
}
else if (metadata.host().equals(host)) { (2)
LOG.info("Found data for key {} locally", id);
Aggregation result = getWeatherStationStore().get(id);
if (result != null) {
return GetWeatherStationDataResult.found(WeatherStationData.from(result));
}
else {
return GetWeatherStationDataResult.notFound();
}
}
else { (3)
LOG.info(
"Found data for key {} on remote host {}:{}",
id,
metadata.host(),
metadata.port()
);
return GetWeatherStationDataResult.foundRemotely(metadata.host(), metadata.port());
}
}
public List<PipelineMetadata> getMetaData() { (4)
return streams.allMetadataForStore(TopologyProducer.WEATHER_STATIONS_STORE)
.stream()
.map(m -> new PipelineMetadata(
m.hostInfo().host() + ":" + m.hostInfo().port(),
m.topicPartitions()
.stream()
.map(TopicPartition::toString)
.collect(Collectors.toSet()))
)
.collect(Collectors.toList());
}| 1 | Se obtiene la metadata de los flujos para el id de estación meteorológica dado |
| 2 | La clave dada (ID de la estación meteorológica) es gestionada por el nodo de la aplicación local, es decir, puede responder la consulta por sí mismo |
| 3 | La clave dada es gestionada por otro nodo de aplicación; en este caso se devolverá la información sobre ese nodo (host y puerto) |
| 4 | El método getMetaData() es agregado para proporcionar a los clientes una lista de todos los nodos del clúster de la aplicación. |
El tipo GetWeatherStationDataResult debe ajustarse en consecuencia:
package org.acme.kafka.streams.aggregator.streams;
import java.util.Optional;
import java.util.OptionalInt;
import org.acme.kafka.streams.aggregator.model.WeatherStationData;
public class GetWeatherStationDataResult {
private static GetWeatherStationDataResult NOT_FOUND =
new GetWeatherStationDataResult(null, null, null);
private final WeatherStationData result;
private final String host;
private final Integer port;
private GetWeatherStationDataResult(WeatherStationData result, String host,
Integer port) {
this.result = result;
this.host = host;
this.port = port;
}
public static GetWeatherStationDataResult found(WeatherStationData data) {
return new GetWeatherStationDataResult(data, null, null);
}
public static GetWeatherStationDataResult foundRemotely(String host, int port) {
return new GetWeatherStationDataResult(null, host, port);
}
public static GetWeatherStationDataResult notFound() {
return NOT_FOUND;
}
public Optional<WeatherStationData> getResult() {
return Optional.ofNullable(result);
}
public Optional<String> getHost() {
return Optional.ofNullable(host);
}
public OptionalInt getPort() {
return port != null ? OptionalInt.of(port) : OptionalInt.empty();
}
}Además, se debe definir el tipo de retorno para getMetaData()
(aggregator/src/main/java/org/acme/kafka/streams/aggregator/streams/PipelineMetadata.java ):
package org.acme.kafka.streams.aggregator.streams;
import java.util.Set;
public class PipelineMetadata {
public String host;
public Set<String> partitions;
public PipelineMetadata(String host, Set<String> partitions) {
this.host = host;
this.partitions = partitions;
}
}Por último, se debe actualizar la clase del endpoint REST:
package org.acme.kafka.streams.aggregator.rest;
import java.net.URI;
import java.net.URISyntaxException;
import java.util.List;
import jakarta.enterprise.context.ApplicationScoped;
import jakarta.inject.Inject;
import jakarta.ws.rs.Consumes;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import jakarta.ws.rs.Produces;
import jakarta.ws.rs.core.MediaType;
import jakarta.ws.rs.core.Response;
import jakarta.ws.rs.core.Response.Status;
import org.acme.kafka.streams.aggregator.streams.GetWeatherStationDataResult;
import org.acme.kafka.streams.aggregator.streams.KafkaStreamsPipeline;
import org.acme.kafka.streams.aggregator.streams.PipelineMetadata;
@ApplicationScoped
@Path("/weather-stations")
public class WeatherStationEndpoint {
@Inject
InteractiveQueries interactiveQueries;
@GET
@Path("/data/{id}")
@Consumes(MediaType.APPLICATION_JSON)
@Produces(MediaType.APPLICATION_JSON)
public Response getWeatherStationData(int id) {
GetWeatherStationDataResult result = interactiveQueries.getWeatherStationData(id);
if (result.getResult().isPresent()) { (1)
return Response.ok(result.getResult().get()).build();
}
else if (result.getHost().isPresent()) { (2)
URI otherUri = getOtherUri(result.getHost().get(), result.getPort().getAsInt(),
id);
return Response.seeOther(otherUri).build();
}
else { (3)
return Response.status(Status.NOT_FOUND.getStatusCode(),
"No data found for weather station " + id).build();
}
}
@GET
@Path("/meta-data")
@Produces(MediaType.APPLICATION_JSON)
public List<PipelineMetadata> getMetaData() { (4)
return interactiveQueries.getMetaData();
}
private URI getOtherUri(String host, int port, int id) {
try {
return new URI("http://" + host + ":" + port + "/weather-stations/data/" + id);
}
catch (URISyntaxException e) {
throw new RuntimeException(e);
}
}
}| 1 | Los datos se encontraron localmente, por lo que se devuelven |
| 2 | Los datos son gestionados por otro nodo, por lo que se debe responder con una redirección (código de estado HTTP 303) si los datos de la clave dada están almacenados en uno de los otros nodos. |
| 3 | No se encontraron datos para el ID de estación meteorológica proporcionado |
| 4 | Expone información sobre todos los hosts que conforman el cluster de la aplicacion |
Ahora detenga de nuevo el servicio aggregator y reconstrúyalo.
Luego, inicie las tres instancias del mismo:
./mvnw clean package -f aggregator/pom.xml
docker-compose stop aggregator
docker-compose up --build -d --scale aggregator=3Al invocar la API REST en cualquiera de las tres instancias, puede ocurrir que la agregación para el ID de la estación meteorológica solicitada este almacenada localmente en el nodo que recibe la consulta, o bien que esté almacenada en uno de los otros dos nodos.
Como el balanceador de carga de Docker Compose distribuirá las solicitudes al servicio aggregator de manera round-robin,
invocaremos los nodos reales directamente.
La aplicación expone información sobre todos los nombres de host mediante REST:
http aggregator:8080/weather-stations/meta-data
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 202
Content-Type: application/json
Date: Tue, 18 Jun 2019 20:00:23 GMT
[
{
"host": "2af13fe516a9:8080",
"partitions": [
"temperature-values-2"
]
},
{
"host": "32cc8309611b:8080",
"partitions": [
"temperature-values-1"
]
},
{
"host": "1eb39af8d587:8080",
"partitions": [
"temperature-values-0"
]
}
]Recupere los datos de uno de los tres hosts mostrados en la respuesta (sus nombres de host reales serán diferentes):
http 2af13fe516a9:8080/weather-stations/data/1Si ese nodo contiene los datos de la clave "1", obtendrás una respuesta como esta:
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 74
Content-Type: application/json
Date: Tue, 11 Jun 2019 19:16:31 GMT
{
"avg": 11.9,
"count": 259,
"max": 50.0,
"min": -30.1,
"stationId": 1,
"stationName": "Hamburg"
}De lo contrario, el servicio enviará una redirección:
HTTP/1.1 303 See Other
Connection: keep-alive
Content-Length: 0
Date: Tue, 18 Jun 2019 20:01:03 GMT
Location: http://1eb39af8d587:8080/weather-stations/data/1También puede hacer que httpie siga automáticamente la redirección pasando la opción --follow:
http --follow 2af13fe516a9:8080/weather-stations/data/1Ejecución Nativa
La extensión de Quarkus para Kafka Streams permite la ejecución de aplicaciones de procesamiento de flujos de manera nativa mediante GraalVM sin necesidad de configuración adicional.
Para ejecutar las aplicaciones producer y aggregator en modo nativo,
las compilaciones de Maven pueden ejecutarse usando -Dnative:
./mvnw clean package -f producer/pom.xml -Dnative -Dnative-image.container-runtime=docker
./mvnw clean package -f aggregator/pom.xml -Dnative -Dnative-image.container-runtime=dockerAhora cree una variable de entorno llamada QUARKUS_MODE y con su valor establecido en "native":
export QUARKUS_MODE=nativeEsto lo utiliza el archivo Docker Compose para emplear el Dockerfile correcto al construir las imágenes de producer y aggregator.
La aplicación Kafka Streams puede funcionar con menos de 50 MB de RSS en modo nativo.
Para ello, agregue la opción Xmx al invocar el programa en aggregator/src/main/docker/Dockerfile.native:
CMD ["./application", "-Dquarkus.http.host=0.0.0.0", "-Xmx32m"]Ahora inicie Docker Compose como se describió anteriormente (no olvide reconstruir las imágenes de los contenedores).
Verificación del estado de Kafka Streams
Si está utilizando la extensión quarkus-smallrye-health, quarkus-kafka-streams añadirá automáticamente:
-
una comprobación de disponibilidad para validar que se han creado todos los tópicos declarados en la propiedad
quarkus.kafka-streams.topics, -
una comprobación de funcionamiento basada en el estado de Kafka Streams.
Así, cuando acceda a la ruta /q/health de su aplicación, obtendrá información sobre el estado de Kafka Streams y los tópicos disponibles y/o faltantes.
Este es un ejemplo de cuando el estado es DOWN:
curl -i http://aggregator:8080/q/health
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 454
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check", (1)
"status": "DOWN",
"data": {
"state": "CREATED"
}
},
{
"name": "Kafka Streams topics health check", (2)
"status": "DOWN",
"data": {
"available_topics": "weather-stations,temperature-values",
"missing_topics": "hygrometry-values"
}
}
]
}| 1 | Comprobación del funcionamiento. También disponible en la ruta /q/health/live. |
| 2 | Comprobación del estado de preparación. También disponible en la ruta /q/health/ready. |
Así que, como puede ver, el estado es DOWN cuando falta uno de los quarkus.kafka-streams.topics o el state de Kafka Streams no es RUNNING.
Si no hay tópicos disponibles, la clave available_topics no estará presente en el campo data de la comprobación del estado de los tópicos de Kafka Streams.
Asimismo, si no falta ningún tópico, la clave missing_topics no estará presente en el campo data de la comprobación del estado de los tópicos de Kafka Streams.
Por supuesto, puede desactivar la comprobación de estado de la extensión quarkus-kafka-streams estableciendo la propiedad quarkus.kafka-streams.health.enabled en false en su application.properties.
Obviamente, puede crear sus sondas de disponibilidad y de preparación basadas en las respectivas rutas /q/health/live y /q/health/ready.
Comprobación del estado (Liveness)
Aquí hay un ejemplo de la comprobación de estado (liveness):
curl -i http://aggregator:8080/q/health/live
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 225
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams state health check",
"status": "DOWN",
"data": {
"state": "CREATED"
}
}
]
}El state viene del enum KafkaStreams.State.
Comprobación del estado de preparación (readiness)
Aquí hay un ejemplo de la comprobación de preparación (readiness):
curl -i http://aggregator:8080/q/health/ready
HTTP/1.1 503 Service Unavailable
content-type: application/json; charset=UTF-8
content-length: 265
{
"status": "DOWN",
"checks": [
{
"name": "Kafka Streams topics health check",
"status": "DOWN",
"data": {
"missing_topics": "weather-stations,temperature-values"
}
}
]
}Ir más allá
This guide has shown how you can build stream processing applications using Quarkus and the Kafka Streams APIs, both in JVM and native modes. For running your KStreams application in production, you could also add health checks and metrics for the data pipeline. Refer to the Quarkus guides on Micrometer, and SmallRye Health to learn more.
Referencia de configuración
Propiedad de configuración fijada en tiempo de compilación - Todas las demás propiedades de configuración son anulables en tiempo de ejecución
Configuration property |
Tipo |
Por defecto |
|---|---|---|
Whether a health check is published in case the smallrye-health extension is present (defaults to true). Environment variable: Show more |
boolean |
|
A unique identifier for this Kafka Streams application. If not set, defaults to quarkus.application.name. Environment variable: Show more |
string |
|
A comma-separated list of host:port pairs identifying the Kafka bootstrap server(s). If not set, fallback to Environment variable: Show more |
list of host:port |
|
A unique identifier of this application instance, typically in the form host:port. Environment variable: Show more |
string |
|
A comma-separated list of topic names. The pipeline will only be started once all these topics are present in the Kafka cluster and Environment variable: Show more |
list of string |
|
A comma-separated list of topic name patterns. The pipeline will only be started once all these topics are present in the Kafka cluster and Environment variable: Show more |
list of string |
|
Timeout to wait for topic names to be returned from admin client. If set to 0 (or negative), Environment variable: Show more |
|
|
The schema registry key. Different schema registry libraries expect a registry URL in different configuration properties. For Apicurio Registry, use Environment variable: Show more |
string |
|
The schema registry URL. Environment variable: Show more |
string |
|
The security protocol to use See https://docs.confluent.io/current/streams/developer-guide/security.html#security-example Environment variable: Show more |
string |
|
SASL mechanism used for client connections Environment variable: Show more |
string |
|
JAAS login context parameters for SASL connections in the format used by JAAS configuration files Environment variable: Show more |
string |
|
The fully qualified name of a SASL client callback handler class Environment variable: Show more |
string |
|
The fully qualified name of a SASL login callback handler class Environment variable: Show more |
string |
|
The fully qualified name of a class that implements the Login interface Environment variable: Show more |
string |
|
The Kerberos principal name that Kafka runs as Environment variable: Show more |
string |
|
Kerberos kinit command path Environment variable: Show more |
string |
|
Login thread will sleep until the specified window factor of time from last refresh Environment variable: Show more |
double |
|
Percentage of random jitter added to the renewal time Environment variable: Show more |
double |
|
Percentage of random jitter added to the renewal time Environment variable: Show more |
long |
|
Login refresh thread will sleep until the specified window factor relative to the credential’s lifetime has been reached- Environment variable: Show more |
double |
|
The maximum amount of random jitter relative to the credential’s lifetime Environment variable: Show more |
double |
|
The desired minimum duration for the login refresh thread to wait before refreshing a credential Environment variable: Show more |
||
The amount of buffer duration before credential expiration to maintain when refreshing a credential Environment variable: Show more |
||
The SSL protocol used to generate the SSLContext Environment variable: Show more |
string |
|
The name of the security provider used for SSL connections Environment variable: Show more |
string |
|
A list of cipher suites Environment variable: Show more |
string |
|
The list of protocols enabled for SSL connections Environment variable: Show more |
string |
|
Trust store type Environment variable: Show more |
string |
|
Trust store location Environment variable: Show more |
string |
|
Trust store password Environment variable: Show more |
string |
|
Trust store certificates Environment variable: Show more |
string |
|
Key store type Environment variable: Show more |
string |
|
Key store location Environment variable: Show more |
string |
|
Key store password Environment variable: Show more |
string |
|
Key store private key Environment variable: Show more |
string |
|
Key store certificate chain Environment variable: Show more |
string |
|
Password of the private key in the key store Environment variable: Show more |
string |
|
The algorithm used by key manager factory for SSL connections Environment variable: Show more |
string |
|
The algorithm used by trust manager factory for SSL connections Environment variable: Show more |
string |
|
The endpoint identification algorithm to validate server hostname using server certificate Environment variable: Show more |
string |
|
The SecureRandom PRNG implementation to use for SSL cryptography operations Environment variable: Show more |
string |
|
About the Duration format
To write duration values, use the standard You can also use a simplified format, starting with a number:
In other cases, the simplified format is translated to the
|